Archive
Semantic Blogging Redux
A while back I posted something about WordPress’ taxonomy model. At the time I thought it was clever and thought we should use something like it for the DotNetNuke Blog module. Now, I’m less enamored with it.
Here’s why.
To recap, have a look at this database diagram:
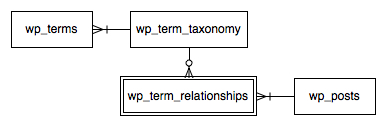
The seeming coolness stemmed from the decision to make “terms” unique, regardless of their use, and to build various taxonomies from them using the wp_term_taxonomy structure. So let’s say you have the term “point-and-shoot”, and you use that as both a tag and a category. “Point-and-shoot” exists once in the wp_terms table and twice in the wp_term_taxonomy table – each entry indicating the term’s inclusion in two different structures. This seems useful because the system “understands” that the tag “point-and-shoot” and the category “point-and-shoot” both mean the same thing.
But is that always a safe assumption?
Consider the case of a photo blog, where the writer is posting photos and writing a little about each. This photographer has a professional studio, and also shoots portraits in public locations, as well as impromptu shots at parties.
This photographer has set up a category structure indicating the situation in which the photo was taken “Studio/Location/Point-and-Shoot” (meaning, an impromptu photograph) and another structure or set of tags indicating what sort of camera was used “Point-and-Shoot”, as opposed to “DSLR”.
Same term. Two completely different meanings. Use that term as a search filter and you will get two sets of results, possibly mutually exclusive.
And so – to truly be “semantic”, the term cannot exist independently of its etymology (as expressed in the category hierarchy) as WordPress attempts to implement.

You must be logged in to post a comment.